InstructLab Research | Red Hat AI Innovation Team
Recent Papers
A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods [arXiv]
Isha Puri, Shivchander Sudalairaj, Guangxuan Xu, Kai Xu, Akash SrivastavaUnveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs [ICLR, arXiv]
Aldo Pareja, Nikhil Shivakumar Nayak, Hao Wang, Krishnateja Killamsetty, Shivchander Sudalairaj, Wenlong Zhao, Seungwook Han, Abhishek Bhandwaldar, Guangxuan Xu, Kai Xu, Ligong Han, Luke Inglis, Akash SrivastavaDr. SoW: Density Ratio of Strong-over-weak LLMs for Reducing the Cost of Human Annotation in Preference Tuning [arXiv]
Guangxuan Xu, Kai Xu, Shivchander Sudalairaj, Hao Wang, Akash SrivastavaLAB: Large-Scale Alignment for ChatBots [arXiv]
Shivchander Sudalairaj, Abhishek Bhandwaldar, Aldo Pareja, Kai Xu, David D. Cox, Akash Srivastava
Recent Posts
Update 3 - On Reasoning vs Inference-time scaling - Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
Written by Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona, GX Xu of the Red Hat AI Innovation Team Th...
Update 2 - Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
Written by Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona, GX Xu This is the second update on our jou...
Update 1 - Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
Written by Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona, GX Xu This is the first update on our jour...
Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
Written by Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona, GX Xu Disclaimer: We have been working on ...
InstructLab
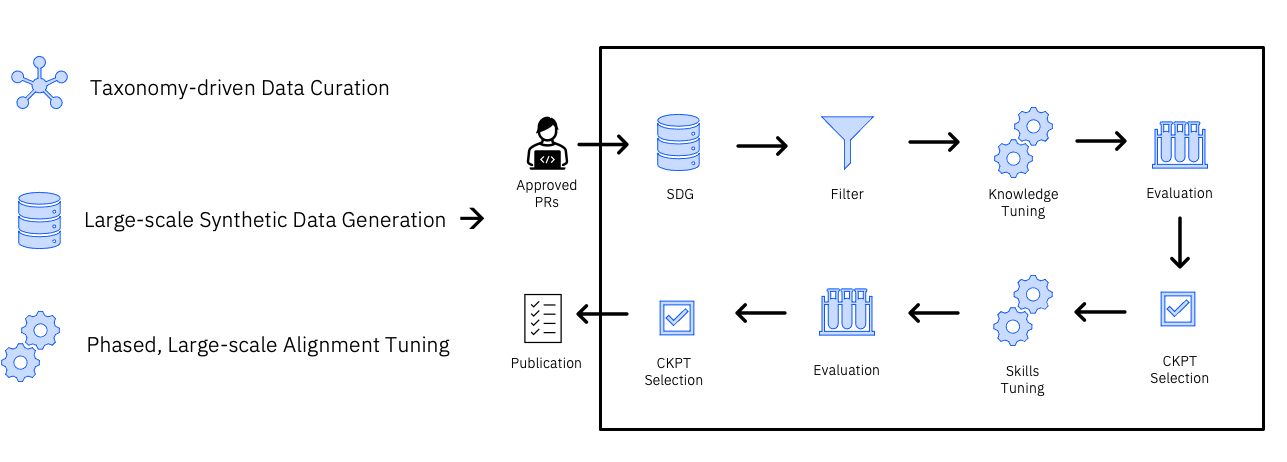
What is InstructLab?
InstructLab is a method for cutomizing large language models (LLMs) to enhance their capabilities. It replaces costly human annotations with taxonomy-guided synthetic data creation and introduces a multi-phase training framework that effectively fine-tunes LLMs on new knowledge and skills. InstructLab provides a scalable, cost-efficient approach for improving LLM performance and instruction-following behavior at target domains. By enabling individual developers and small organizations to incorporate their own data sources, InstructLab facilitates continuous knowledge and skill acquisition, making LLMs more accessible and adaptable.
Customizing LLMs for Domain-Specific Expertise
Customizing LLMs from general-purpose tools into domain-specific experts is increasingly in demand by enterprises and individual developers. It enables LLMs to align with organizational guidelines and specialize in relevant areas of expertise. InstructLab offers a solution for model customization, taking any small-sized LLM and using synthetic data creation combined with multi-phased training to infuse the model with domain-specific knowledge and skills. These specialized models can then be deployed for enterprise purposes, offering cost-efficient inference and the ability to run on consumer-grade hardware, making them accessible to smaller organizations while providing full control over data and models.
Media Press
- IBM Thinks Small to Win Enterprise AI [MSN]
- IBM Granite 3.0: Practical Open-Source LLM For Enterprise Applications [Forbes]
- Red Hat Accelerates Generative AI Innovation with Red Hat Enterprise Linux AI on Lenovo ThinkSystem Servers [Yahoo Finance]
- L'intelligence artificielle et la puissance des logiciels open source [Le Figaro]