Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
in 4 days, with 80 H100s (later with an extra 64 H200s, from friends)
Written by Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona, GX Xu
of the Red Hat AI Innovation Team
Disclaimer:
We have been working on this nonstop since the ICML deadline and have lost some of the incredible Shakespearean writing abilities that we traditionally possess. Apologies for any mistakes or sloppiness, we will soon ply ourselves with sugar and return better than ever!
This is also a live doc, so we will be updating the sections (especially the recipe/results!) as we get results day by day! We will continue to add more code/details/make this more robust as we go. Join us for our chaotic yellow brick road journey to Oz R1!
Our journey in R1-like reasoning starts from how CoT data was synthesized to improve models.
CoT: The LLM community’s journey to inference scaling begins long, long ago with the arrival of CoT - aka Chain of Thought. In their 2022 paper, the team over at Google Brain discovered that just asking models to “think step by step” before answering a question boosted reasoning ability - simply by structuring the model’s response as a sequence of logical steps.
Orca: Researchers soon realized that prompting alone had its limits. While CoT-style reasoning helped models on some reasoning benchmarks, it wasn’t an inherent skill the models possessed - it was just an artifact of the inference time prompt. Microsoft’s Orca paper tackled this problem head on by distilling intermediate reasoning steps from GPT-4 into smaller models. Instead of just training a model to generate correct final answers, Orca explicitly supervised the reasoning process by encouraging models to imitate the structured, step-by-step reasoning of stronger models. This created a fundamental shift - instead of just CoT-style prompting, we were now CoT-style training, assigning reasoning to be an explicit learned objective. We also realized that smaller models could punch above their weight, so to speak, by mimicking the reasoning structures of more powerful models.
Tree/Forest of Thought and Beam Search: While CoT/Orca focused on single threads of reasoning, there was still a gap. Human problem solving is not linear! We explore multiple different solutions before deciding on just one! This insight leads us to Tree of Thought, where models generate multiple reasoning paths and explore different possible steps before committing to a final answer. Instead of solving problems in a single pass, Tree of Thought branches into multiple possibilities, evaluates and prunes bad reasoning paths, and in general allows for self correction and more robust decision making. Forest of Thought extended this idea by allowing parallel rees explore multiple reasoning paradigms at once.
Process Supervision:
At this stage, a crucial problem emerges. Even if a model generates a correct answer, its reasoning process may be unreliable or produce shortcut solutions! We need a way to validate the process of thinking itself - indeed, this is what we learned in school - show your work! This leads us to process supervision, where models are rewarded not just for getting the right answer, but also for following a reasoning path that aligns with human expectations. Unlike general outcome based reward models, Process Supervision evaluates the logical correctness of each intermediate step. If a model follows a flawed but correct-looking reasoning chain, it is penalized even if the final answer is correct. This is where we introduce Process Reward Models, which learn to predict the likelihood of each reasoning step being correct. By using PRMs, we get more granular control over the logical consistency of a model’s reasoning steps. They offer a pathway towards allowing models to self-verify and guide their own reasoning trajectories.
Inference Scaling:
We have arrived at the Inference Time Scaling stop on our journey through time! Inference scaling refers to methods that improve a model’s reasoning ability and performance at runtime, without any requiring additional training or fine tuning! As shown by the Large Language Monkeys paper that came out of Stanford, many small, open sourced language models will eventually produce a correct answer for even challenging problems when prompted enough times. This suggests that smaller language models have better performance ability locked up within them - we just have to coax it out of them! The question then becomes - how can we intelligently navigate the space of the LM’s possible answers to help it achieve its full potential?
This is where our method comes in!
So what's wrong with current inference scaling methods?
Well, many current inference-time scaling methods "guide" their search process with Process Reward Models—off-the-shelf models that take a problem and a (partial or complete) answer and return a reward score. These methods (beam search, DVTS, etc) take the "top-N" options at every step and explore these.
The problem, however, is that PRMs, as in the case of almost all Reward Models, are imperfect. They are often inadequate approximations of the ground truth, and following them leads to Reward Hacking, where the final output is optimized to score well according to the reward model but fails to be useful and/or correct.
This is where our method comes in. We ask the following:
Can we frame inference-time scaling as a probabilistic inference task?
What do we do differently?
Instead of allowing the PRM to completely determine which answers we unroll further, we do the following:
For a super easy-to-understand, intuitive explanation of our method, see this video!
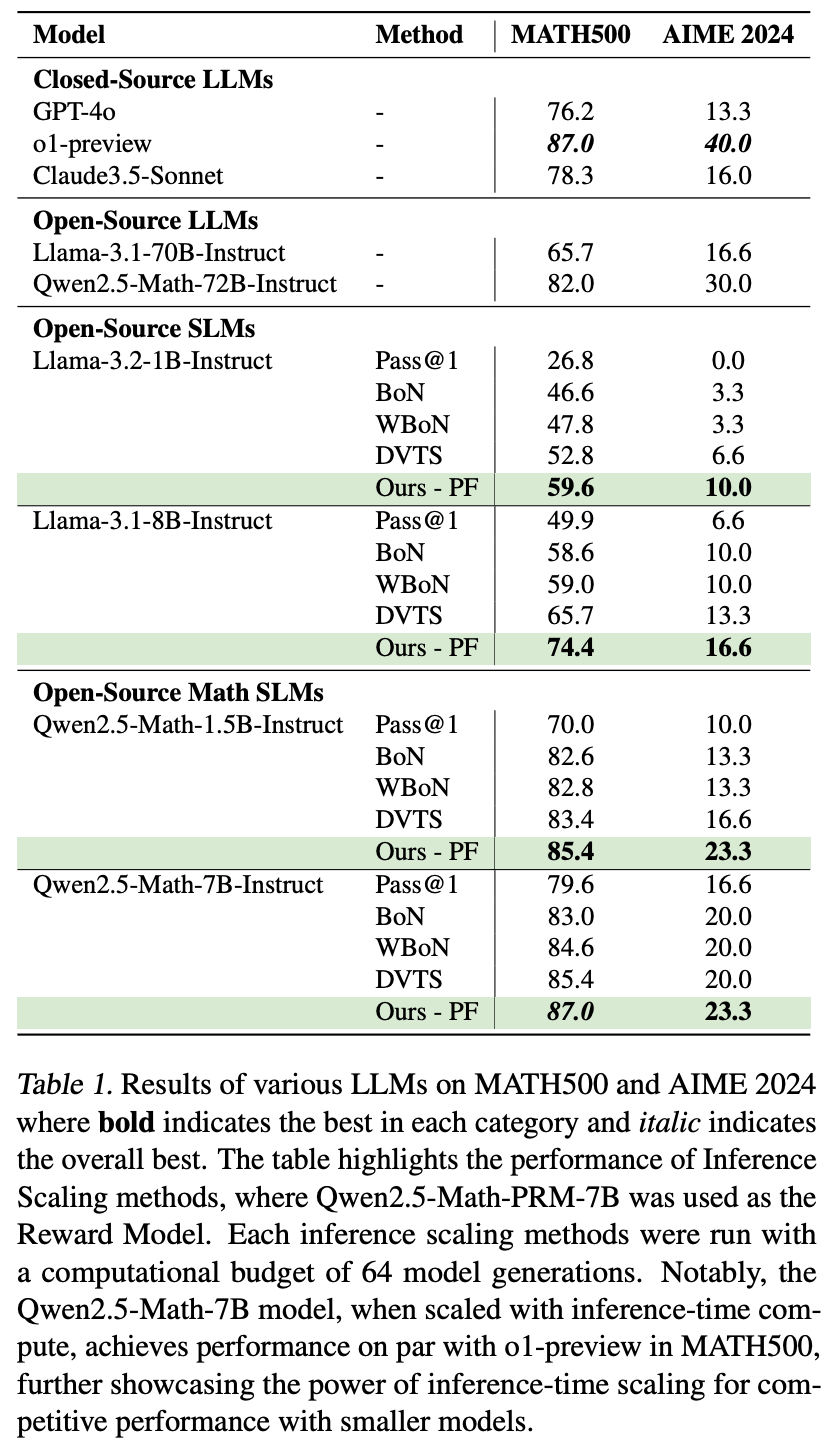
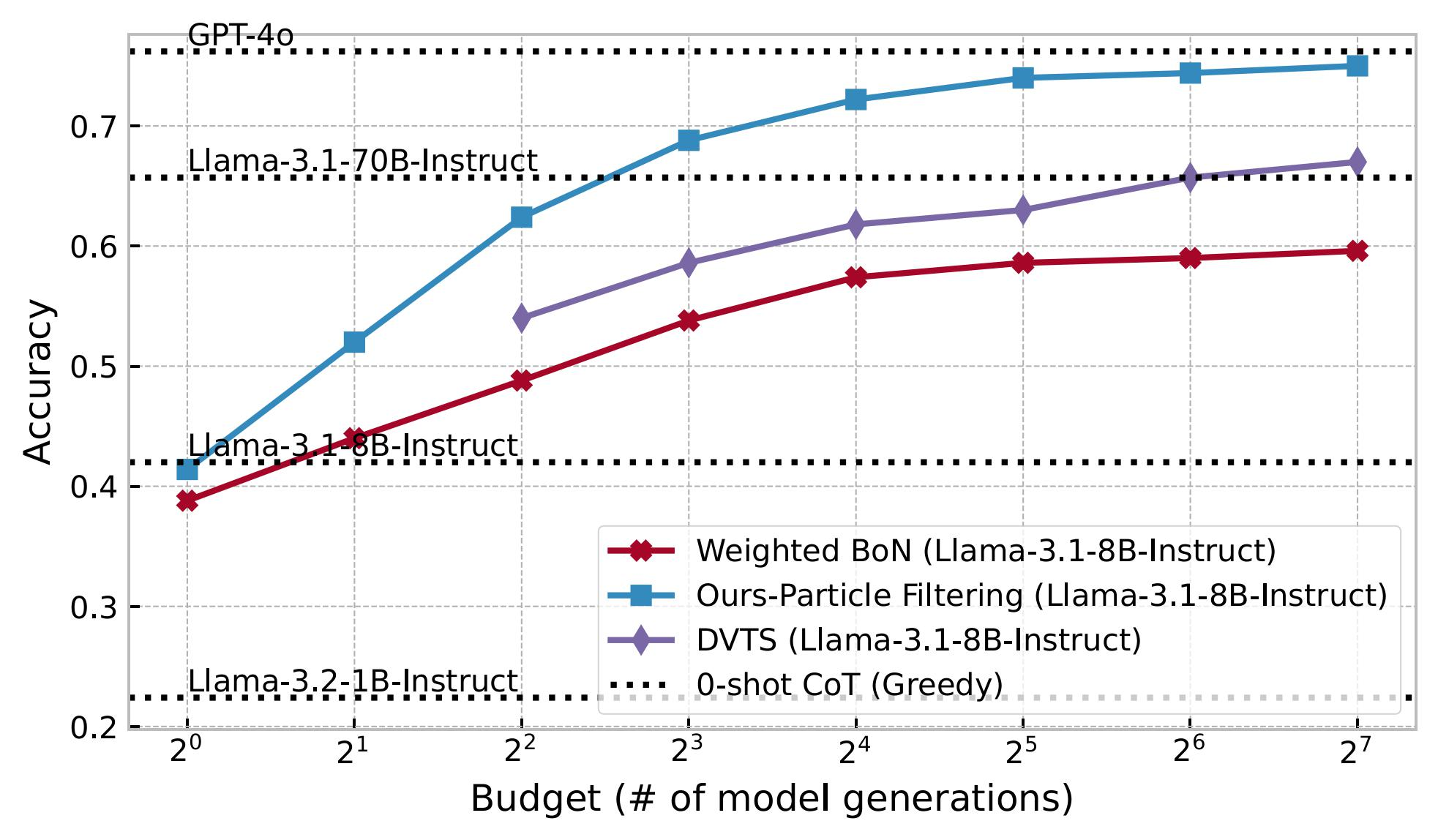
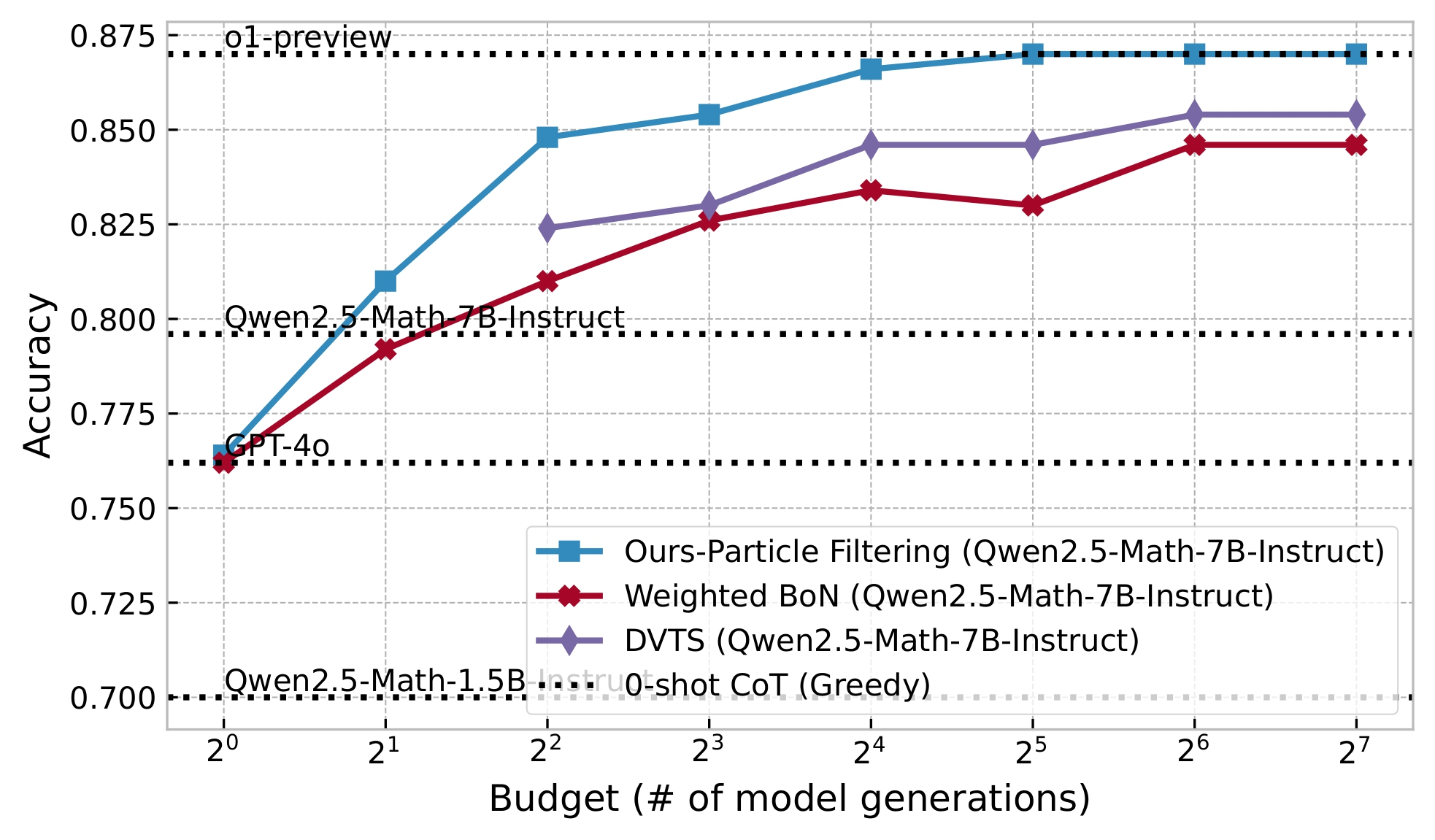
So what are our results?
We get some very cool numbers!
Our method scales 4-16x better than the deterministic inference scaling methods out there.
On the MATH dataset, our method:
Why is this so cool?
We do all of this - scaling small models to such fantastic numbers - without training anything at all! Our method is able to efficiently guide a small, open source off-the-shelf model to “discover its potential” and make truly staggering improvements, just by intelligently navigating the search space!
Just to provide some comparison points, this recent work https://arxiv.org/pdf/2502.02508 trains a base model on trajectories generated from Qwen-2.5-Math-7B-Instruct and achieves an accuracy of 85.6% on MATH500, while our method is able to get to an accuracy of 87% just by milking the Qwen 2.5 Math 7B Instruct model itself for all its worth. Our results underline the novelty and elegance of this inference scaling method and again points to the core idea - how can we guide a language model through a search space to help it reach its full potential?
Inference-time scaling is pretty wild—it lets us take a (relatively speaking) small model and boost its performance to rival some of the biggest names in mathematical reasoning benchmarks (OpenAI’s o1 for example). In simple terms, this means a tiny model (or for the RL folks, the policy) actually can reason mathematically, given the right conditions. But that raises the obvious question: how do we train a model to learn to inference-scale instead of orchestrating it with a PRM, at runtime?
Let’s break it down. As we saw earlier, inference-time scaling needs a method—like best-of-N (BoN) or particle filtering—and a reward model. This setup can be super expensive to run. So, how do we make it cheaper? One way is to train the model to imitate the inference-time scaling method (learn to generate trajectories similar to particle filtering or beam search) and self-evaluate (to replace PRM/ORM) its own reasoning before locking in an answer. Basically, instead of paying the full cost every time we run inference, we get the model to internalize the process through training.
Training Models to Learn Inference-Time Scaling
So how do we actually do this? Well, we already have most of the pieces in place: a policy, a reward model, and an exploration method. If we throw in a reinforcement learning approach—like PPO or GRPO—we can close the loop and teach the model to “think” or “reason” on its own.
But that’s not the only approach. Another way is to use a small or a larger teacher model to generate trajectory data using inference time-scaling first. We can then fine-tune a smaller model with Supervised Fine-Tuning (SFT), and maybe follow it up with GRPO to reinforce the best reasoning strategies.
Learning from R1: A Model That Knows When to Backtrack
Lately, I’ve been fascinated by R1’s approach. What stands out is how it generates multiple answers, evaluates them at intermediate steps or at the end, and then decides whether to backtrack, restart, or finalize an answer if it thinks it’s correct. This feels eerily similar to how a model under particle filtering would behave—exploring different paths before settling on the best one.
Of course, the “oh wait” moments (aka reflections 😆) aren’t as organic here because a reward model is guiding the process. But it’s still super impressive that DS managed to set up conditions where the model learned inference-time scaling just by using RL. The downside? Running that process requires a ton of compute, way more than we’d like to spend.
So instead, we’re taking what we’ve learned—that “it's likely” that training a model to learn inference-time scaling leads to reasoning-like abilities—and using it to make small models smarter.
A Live Experiment Blog
The next section is where things get real. We’re going to document our experiments in real time—sharing our code, models, ideas, and results (including what didn’t work). The goal? Finding a more efficient way to make small models reason like o1 and R1—without the ridiculous compute costs. Let’s figure this out together. 🚀
Building on our findings of inference-time scaling methods, we come up with a recipe to bake R1-like reasoning ability to small LLMs efficiently.
First of all, how is DeepSeek-R1 trained? DeepSeek-R1 is trained in a few phases:
If you’re curious about steps 4 and 5, here’s a paper from our team explaining how to do this without human annotations: https://arxiv.org/abs/2411.02481.
So now we are looking for a way to obtain R1-like reasoning in small LLMs. We came up with a recipe that does not use DeepSeek-R1 nor its derivatives, and that is we are working on at the moment. Here is a side-by-side comparison between DeepSeek’s approach and our recipe.
DeepSeek | Us | |
R1-Zero / Reasoning Data | R1-Zero (???B), few-shot CoT, reflection-verification prompting | Phi-4 (14B) w/ inference-time scaling (BoN, Gibbs, PF) |
Warm Start | DeepSeek-V3-base (???B) | Granite-3.1-Lab (8B), Llama-3.1-Instruct (8B), Phi-4 (14B) |
RL for Reasoning | GRPO | GRPO |
General Capability | Rejection Sampling + SFT -> Preference Tuning | DPO w/ Dr. SoW |
Here's a breakdown
Disclaimer:
These results are a messy, chaotic, absolutely massive work in progress, and we’ll update code and results as we continue to get them! We have not gotten very much sleep and we sincerely apologize for any gaps in the results table. Please pray to the gods of LLMs with us to help populate it! Thank you for your cooperation <3
Bespoke Dataset: A Good Start, but Not Enough
Like pretty much everyone else, we kicked things off by working with the reasoning dataset created by Bespoke. From what we know, it’s distilled from R1, making it a solid starting point. But for our specific experiments, it didn’t quite hit the mark. Still, we wanted to see how far small models could go by just fine-tuning (SFT) on this dataset—and more importantly, whether training on a math-heavy reasoning dataset could help generalize the model’s reasoning ability to non-math tasks.
Turns out, it kinda worked! Training on this dataset did help smaller Granite and Llama models mimic R1-like reasoning patterns. However, there was a catch: while they looked like they were reasoning, their actual benchmark performance didn’t improve after SFT.
So, we took the best SFT checkpoint and ran GRPO on it, hoping that the reasoning skills bootstrapped during fine-tuning would become more refined. Once again… no major improvement in benchmarks for Llama or Granite.
BoN with Phi-4: Prompting It to Think
After some quick brainstorming and research, we decided to give Phi-4 a shot. This model is seriously underrated—it performs ridiculously well on nearly every benchmark and even shows promising reasoning skills, at least in math. Best part? It’s only 14B parameters and fully open source. Huge shoutout to Microsoft Research for that one! 🎉
Given our past work with InstructLab, we like to think we know a thing or two about synthetic data generation (SDG) 😆. So, it didn’t take long to figure out how to prompt Phi-4 into generating reasoning trajectories.
Here’s what we did:
This time, we saw some really interesting results:
✅ Math scores improved for Llama
✅ AIME scores improved
✅ It even solved a problem posed by our chief scientist 😆
What We Learned: Two Big Gaps
After looking at our results (and a bit of soul-searching 😛), we realized two major issues in how our models reasoned compared to R1:
1️⃣ Short responses: Our model’s answers were too concise—R1-style reasoning tends to be longer.
2️⃣ No backtracking: The model wasn’t self-reflecting or revising its own answers. We had hoped GRPO would make this emerge naturally, but it didn’t.
What’s Next: Iterating on Phi-4 as Teacher & Student
Back to the whiteboard we went! One key insight: maybe it’s just too hard for an 8B model to develop reflection without being explicitly trained on reflection examples. R1 does this, so maybe we need to as well.
Since R1’s own paper suggests that the model being trained with RL needs to be reasonably strong, we decided to keep using Phi-4—not just as the teacher, but also as the student in our next experiments. Stay tuned. 🚀
—
Teaching Models to Revise Their Own Thinking
Naïve Stitch: Making Mistakes on Purpose (and Fixing Them!)
Our first shot at making the model reason more like R1 was pretty simple: force it to revise its own mistakes. We took our BoN-generated data and created what we’re calling D-stitch.
Here’s how it works:
1. For each question, we start with the thought process from a wrong sample.
2. Then, we add a transition phrase like “Hold on! I made a mistake. Let me try again.”
3. Finally, we append the thought process and solution from a verified correct sample.
4. Bonus: We can add more than one wrong thought before the correct one!
The results? A slight improvement, but the real win was that the model actually started revising its full reasoning process. That’s a good sign! Encouraged by this, we decided to push further and generate even more R1-like training data.
PF Backtrack: Getting the Model to Doubt Itself
While revising an entire answer is nice, it’s still not quite the reasoning we’re after. What we really want is partial backtracking—where the model recognizes errors midway, doubts itself, and changes course like R1.
This reminded us of something: particle filtering (or any tree search method). Algorithmically, this kind of reasoning looks a lot like pruning bad search paths in a tree. So, we decided to generate backtrack data using particle filtering.
Here’s how we did it:
• We ran our particle filtering method, recording all the “dead” particles at each step (basically, failed reasoning paths).
• This gave us a search tree where we could verify the final solutions from the correct paths.
• We then synthesized new reasoning data by intentionally stitching in incorrect branches before returning to a correct path.
• Whenever the model backtracked, we added a phrase like “Hold on! I made a mistake. Let me try again.”
We’re calling this dataset D-backtrack, and it’s designed to train models to doubt and backtrack at intermediate steps, not just at the end.
Gibbs with “But Wait”: Inspired by S1
While we were working on this, the S1 paper (🔗 https://arxiv.org/abs/2501.19393) dropped, giving us even more ideas! Inspired by their approach, we created D-but-wait, a dataset designed to push the model toward deeper reasoning.
Here’s how we built it:
This setup encourages the model to naturally question its first thought, a bit like Gibbs sampling where you iterate until the solution stabilizes.
Next Steps: Refining Backtracking and Doubt Mechanisms
With these different approaches—D-stitch, D-backtrack, and D-but-wait—we’re getting models that at least attempt to revise themselves. But there’s still more to do! We’re now exploring how to make backtracking even more structured and whether we need larger models to fully develop this behavior.
Let’s see where this takes us. 🚀
—
Model | Dataset | Method | AIME 2024 (Pass@8) | MATH500 (Pass@8) |
- | - | 6/30 | 73.6 | |
SFT | ⏳ | ⏳ | ||
Think-v1-13k (ours) | SFT + GRPO | 7/30 | 80.2 | |
- | - | 12/30 | 88.2 | |
Think-v1-13k (ours) | SFT + Dr.SoW | 10/30 | 90.8 | |
But-wait-10k (ours) | SFT + GRPO | 10/30 | 87.8 | |
Backtrack-22k | SFT + GRPO | 10/30 | ⏳ |
—
Updates: Feb 6th 2025
Today was mostly about organizing results, evaluating new checkpoints, and making sense of all the numbers. We also kicked off a fresh experiment to test the impact of data quality on reasoning in small LLMs—but more on that later.
Granite + Particle Filtering = Big Gains 📈
We already knew from our earlier experiments that particle filtering works well across multiple small models. But as we were compiling today’s results, we found something even more exciting: Granite models also benefit significantly from our method! 🎉
Here’s how Granite 8B performed on the key benchmarks:
✅ MATH-500: 0.78 (Granite 8B)
✅ AIME 2024: 16.6 (Granite 8B)
This is huge—our particle filtering method actually makes Granite better than GPT-4o on Math-500 and AIME 2024! 🎉🎉
More Cool Results 🔥
Across the board, introducing reasoning—using all the methods we talked about earlier—led to consistent performance gains on the Math-500 and AIME 2024 benchmarks. Here’s a giant results table summarizing where we stand (adding it here soon 👀).
model | dataset | ckpt | (expected) aime@1 | aime@8 | note |
deepseek-ai/DeepSeek-R1-Distill-Llama-8B | - | - | 33.75 | 66.67 | baselines/aime/DeepSeek-R1-Distill-Llama-8B |
meta-llama/Llama-3.1-8B-Instruct | - | - | 2.92 | 10.00 | baselines/aime/Llama-3.1-8B-Instruct (This is without a specific prompt) |
Llama-3.1-8B-Instruct | Bespoke-prompt | llama-r1-bmo-bespoke-system-numinamath/samples_819150 | 5.83 | 16.67 | |
Llama-3.1-8B-Instruct | Bespoke-prompt + grpo | new_grpo_llama_solo/ckpt-105 | 7.08 | 20.00 | |
Llama-3.1-8B-Instruct | Bespoke-prompt + grpo | new_grpo_llama_solo/ckpt-120 | 7.50 | 20.00 | Our best llama |
Llama-3.1-8B-Instruct | Bespoke-prompt + grpo | new_grpo_llama_solo/ckpt-135 | 5.83 | 20.00 | |
Llama-3.1-8B-Instruct | Bespoke-prompt + grpo | new_grpo_llama_solo/ckpt-150 | 6.25 | 20.00 | |
ibm-granite/granite-3.1-8b-instruct | - | - | 1.25 | 3.33 (was 10.00) | |
microsoft/phi-4 | - | - | 19.17 | 43.33 | baselines/aime/phi-4 |
Phi-4 | Bespoke-prompt | (add sft here) | |||
Phi-4 | Bespoke-prompt + grpo | phi-r1-test-new-checkpoint-75 | 18.33 | 36.67 | |
Phi-4 | Bespoke-prompt + grpo | new_grpo_phi/ckpt-90 | 15.42 | 33.33 | |
Phi-4 | Bespoke-prompt + grpo | new_grpo_phi/ckpt-105 | 13.75 | 30.00 | |
Phi-4 | Backtrack | numinamath-phi4-traj-8x1-0.8-backtracked_numinamath_phi_4/samples_209128 | 16.67 | 36.67 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-165 | 12.08 | 26.67 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-255 | 14.58 | 30.00 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-285 | 13.33 | 26.67 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-315 | 16.25 | 43.33 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-405 | 15.00 | 26.67 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-450 | 15.83 | 23.33 | |
Phi-4 | Backtrack + grpo (beta 0.01) | grpo_backtrack_phi_beta_01/ckpt-465 | 16.25 | 33.33 | |
Phi-4 | But-Wait | but_wait_numinamath_phi_4/samples_121519 | 17.08 | 36.67 | |
Phi-4 | But-Wait + grpo (beta 0.01) | grpo_but_wait_phi_beta_01/ckpt-150 | 18.75 | 38.46 | |
Phi-4 | But-Wait + grpo (beta 0.01) | grpo_but_wait_phi_beta_01/ckpt-210 | 17.08 | 36.67 | |
Phi-4 | But-Wait + grpo (beta 0.01) | grpo_but_wait_phi_beta_01/ckpt-270 | 20.00 | 46.67 | Our best phi |
Phi-4 | But-Wait + grpo (beta 0.01) | grpo_but_wait_phi_beta_01/ckpt-360 | 16.67 | 40.00 | |
Phi-4 | Direct evolution GRPO | grpo_evolution_phi_beta_01/ckpt-15 | 13.75 | 36.67 | |
Phi-4 | Direct evolution GRPO | grpo_evolution_phi_beta_01/ckpt-30 | 15.83 | 26.67 | |
Phi-4 | Direct evolution GRPO MINI | grpo_evolution_mini_phi_beta_01/ckpt-5 | 15.42 | 30.00 | |
Phi-4 | Direct evolution GRPO MINI | grpo_evolution_mini_phi_beta_01/ckpt-10 | 17.08 | 26.67 | |
Phi-4 | Direct evolution GRPO MINI | grpo_evolution_mini_phi_beta_01/ckpt-15 | 16.25 | 33.33 | |
Phi-4 | LIMO- no system prompt. Used <thinking><thinking> and <answer><answer> on the training. | limo_phi_4_lr_6e-6/samples_11159 | 26.00 | 47.00 | LIMO has 817 samples. LIMO has AIME-ish and MATH-ish data. |
Data Quality: A Game-Changer?
We came across this fascinating paper today: 🔗 https://arxiv.org/abs/2502.03387, which dives deep into the importance of data quality in reasoning. The results are wild—they trained a Qwen-32B model on just ~800 high-quality reasoning samples and got O1/R1-level performance on MATH-500 and AIME24!
Naturally, we had to try it out ourselves. And guess what? It worked! Applying the same strategy to Phi-4 gave us Phi-LIMO which is the best performing model so far (investigating the evaluation script as the numbers on the second run turned out to be lower), which is on par with the R1-distilled Llama-8B model
Most Interesting Takeaway of the Day
Our synthetic data-based reasoning methods actually resulted in a Phi-4 model that reasons better than vanilla Phi-4—and it shows its reasoning in the process. That’s a big win for using synthetic data to enhance reasoning capabilities.
What’s Still Running?
Most of our compute is tied up with existing runs, so today we’re launching just two more experiments:
🔹 Testing the LIMO dataset on Granite – Can a really small model develop reasoning with just ~800 high-quality examples? We’ll let you know tomorrow.
🔹 Generating synthetic data using particle filtering on LIMO dataset questions—will this further enhance reasoning abilities?
This is funny so I have to mention it, GPT4-o just told me the following:
Did you know? The human brain makes approx. 35,000 decisions per day, many of them involving subconscious “particle filtering” to evaluate possible outcomes. Teaching LLMs to backtrack and refine their reasoning is, in a way, mimicking our own decision-making process.
What? 🤯
—
Updates: Feb 7th 2025
Today’s Updates: More Experiments, More Insights
Yesterday, we ran two new experiments to push our small models even further:
🔹 Testing the LIMO dataset on Granite – Can a really small model develop reasoning abilities with just ~800 high-quality examples?
Unfortunately, this one didn’t pan out. Neither Llama nor Granite showed much improvement, even though this dataset significantly boosted Phi-4’s performance. The original paper demonstrated strong results on Qwen-32B, but based on our experiment, it’s clear that the effectiveness of this approach is very model-dependent.
In short: Qwen-32B is just a beast. It already has strong mathematical and reasoning abilities, so training on a relatively tiny dataset helps refine what’s already there. For smaller models? Not so much. (Guess there’s no such thing as a free lunch after all! 😅)
🔹 Generating synthetic data using particle filtering on LIMO dataset questions – Could this enhance reasoning abilities?
This one was interesting! Running Phi-4 with our particle filtering-based inference scaling method, it successfully solved about half of the ~800 LIMO problems using a 512-particle count.
Here’s what happened next:
What’s Next? New Experiments Underway 🚀
We finally killed off our older GRPO runs after running them for quite a few iterations. The reason? The reward had plateaued, and the trained models showed no further improvements on AIME24.
At this point, I’m starting to wonder: Is AIME24 just too difficult for small models unless they’ve been trained with distilled data from larger reasoning models? 🤔 We’ll keep using it for now, but we might reconsider another benchmark later.
Today, we launched two new experiments:
🔹 GRPO on “But Wait” Phi Checkpoint & LIMO Questions
🔹 Introducing GRPO-Direct
1. Generate synthetic data inside GRPO itself.
2. Immediately train the model on it within the same loop.
We’re running this on the LIMO dataset, using a Phi checkpoint that has already been trained on synthetic data it generated from the 380 LIMO samples.
If you want to cite this blog post, you can use the following BibTeX entry
@misc{srivastava2024lessonsonreproducing,
title={Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)},
author={Akash Srivastava, Isha Puri, Kai Xu, Shivchander Sudalairaj, Mustafa Eyceoz, Oleg Silkin, Abhishek Bhandwaldar, Aldo Genaro Pareja Cardona and GX Xu},
url={https://red-hat-ai-innovation-team.github.io/posts/r1-like-reasoning},
year={2025},
}